This post will talk about a new library in Go 1.7, the context library, and when or how to correctly use it. Required reading to start is the introductory post that talks a bit about the library and generally how it is used. You can read documentation for the context library on tip.golang.org.
How to integrate Context into your API Link to heading
The most important thing to remember when integrating Context into your API is that it is intended to be request scoped. For example, it would make sense to exist along a single database query, but wouldn’t make sense to exist along a database object.
There are currently two ways to integrate Context objects into your API:
- The first parameter of a function call
- Optional config on a request structure
For an example of the first, see package net’s Dialer.DialContext. This function does a normal Dial operation, but cancels it according to the Context object.
func (d *Dialer) DialContext(ctx context.Context, network, address string) (Conn, error)
For an example of the second way to integrate Context, see package net/http’s Request.WithContext
func (r *Request) WithContext(ctx context.Context) *Request
This creates a new Request object that ends according to the given Context.
Context should flow through your program Link to heading
A great mental model of using Context is that it should flow through your program. Imagine a river or running water. This generally means that you don’t want to store it somewhere like in a struct. Nor do you want to keep it around any more than strictly needed. Context should be an interface that is passed from function to function down your call stack, augmented as needed. Ideally, a Context object is created with each request and expires when the request is over.
The one exception to not storing a context is when you need to put it in a struct that is used purely as a message that is passed across a channel. This is shown in the example below.
package main
import (
"fmt"
"golang.org/x/net/context"
)
// A message processes parameter and returns the result on responseChan.
// ctx is places in a struct, but this is ok to do.
type message struct {
responseChan chan<- int
parameter string
ctx context.Context
}
func ProcessMessages(work <-chan message) {
for job := range work {
select {
// If the context is finished, don't bother processing the
// message.
case <-job.ctx.Done():
continue
default:
}
// Assume this takes a long time to calculate
hardToCalculate := len(job.parameter)
select {
case <-job.ctx.Done():
case job.responseChan <- hardToCalculate:
}
}
}
func newRequest(ctx context.Context, input string, q chan<- message) {
r := make(chan int)
select {
// If the context finishes before we can send msg onto q,
// exit early
case <-ctx.Done():
fmt.Println("Context ended before q could see message")
return
case q <- message{
responseChan: r,
parameter: input,
// We are placing a context in a struct. This is ok since it
// is only stored as a passed message and we want q to know
// when it can discard this message
ctx: ctx,
}:
}
select {
case out := <-r:
fmt.Printf("The len of %s is %d\n", input, out)
// If the context finishes before we could get the result, exit early
case <-ctx.Done():
fmt.Println("Context ended before q could process message")
}
}
func main() {
q := make(chan message)
go ProcessMessages(q)
ctx := context.Background()
newRequest(ctx, "hi", q)
newRequest(ctx, "hello", q)
close(q)
}
In this example, we break this general rule of not storing Context by putting it in a message. However, this is an appropriate use of Context because it still flows through the program, but along a channel rather than a stack trace. Also notice here how the Context is used in four places:
- To time out q in case the processor is too full
- To let q know if it should even process message
- To time out q sending the message back to newRequest()
- To time out newRequest() waiting for a response back from ProcessMessage
All blocking/long operations should be cancelable Link to heading
When you take away the ability for users to cancel long-running operations, you tie up a goroutine longer than the user wants. With Context moving into the standard library with Go 1.7, it will easily become the standard abstraction for timing out or ending early long-running operations. If you are writing a library and your functions may block, it is a perfect use case for Context.
In the example above, ProcessMessage is a quick operation that does not block so the context is obviously overkill. However, if it was a much longer operation then the use of Context by the caller allows newRequest to move on if it takes too long to calculate.
Context.Value and request-scoped values (a warning) Link to heading
The most contentious part of Context is Value, which allows arbitrary values placed into a Context. The intended use for Context.Value, from the original blog post, is request-scoped values. A request scoped value is one derived from data in the incoming request and goes away when the request is over. As a request bounces between services, this data is often maintained between RPC calls. Let’s first try to clarify what is or is not a request scoped value.
Obvious request scoped data could be who is making the request (user ID), how they are making it (internal or external), from where they are making it (user IP),and how important this request should be.
A database connection is not a request scoped value because it is global for the entire server. On the other hand, if it is a connection that has metadata about the current user to auto-populate fields like the user ID or do authentication, then it may be considered request scoped.
A logger is not request scoped if it sits on a server object or is a singleton of the package. However, if it contains metadata about who sent the request and maybe if the request has debug logging enabled, then it becomes request scoped.
Unfortunately, request scoped data can encompass a large set of information since in some sense all the interesting data in the application comes from a request. This puts a broad definition on what could be included in Context.Value, which makes it easy to abuse. I personally have a more narrow view of what is appropriate in Context.Value and I’ll try to explain my position in the rest of this post.
Context.Value obscures your program’s flow Link to heading
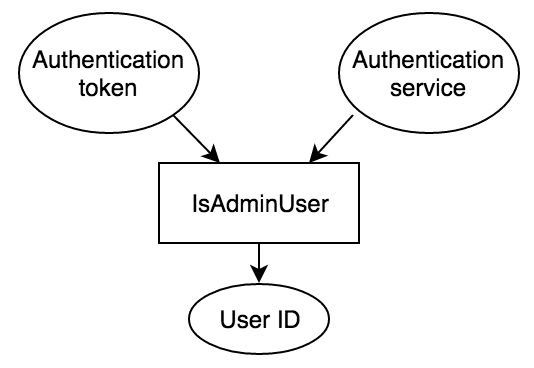
The real reason so many restrictions are placed on proper use of Context.Value is that it obscures expected input and output of a function or library. It is hated by many for the same reasons people hate singletons. Parameters to a function are clear, self-sufficient documentation of what is required to make the function behave. This makes the function easy to test and reason about intuitively, as well as refactor later. For example, consider the following function that does authentication from Context.
func IsAdminUser(ctx context.Context) bool {
x := token.GetToken(ctx)
userObject := auth.AuthenticateToken(x)
return userObject.IsAdmin() || userObject.IsRoot()
}
When users call this function they only see that it takes a Context. But the required parts to knowing if a user is an Admin are clearly two things: an authentication service (in this case used as a singleton) and an authentication token. You can represent this as inputs and outputs like below.
IsAdminUser flow
Let’s clearly represent this flow with a function, removing all singletons and Contexts.
func IsAdminUser(token string, authService AuthService) int {
userObject := authService.AuthenticateToken(token)
return userObject.IsAdmin() || userObject.IsRoot()
}
This function definition is now a clear representation of what is required to know if a user is an admin. This representation is also apparent to the user of the function and makes refactoring and reusing the function more understandable.
Context.Value and the realities of large systems Link to heading
I strongly empathize with the desire to shove items in Context.Value. Complex systems often have middleware layers and multiple abstractions along the call stack. Values calculated at the top of the call stack are tedious, difficult, and plain ugly to your callers if you have to add them to every function call between top and bottom to just propagate something simple like a user ID or auth token. Imagine if you had to add another parameter called “user ID” to dozens of functions between two calls in two different packages just to let package Z know about what package A found out? The API would look ugly and people would yell at you for designing it. GOOD! Just because you’ve taken that ugliness and obscured it inside Context.Value doesn’t make your API or design better. Obscurity is the opposite of good API design.
Context.Value should inform, not control Link to heading
Inform, not control. This is the primary mantra that I feel should guide if you are using context.Value correctly. The content of context.Value is for maintainers not users. It should never be required input for documented or expected results.
To clarify, if your function can’t behave correctly because of a value that may or may not be inside context.Value, then your API is obscuring required inputs too heavily. Beyond documentation, there is also the expected behavior of your application. If the function, for example, is behaving as documented but the way your application uses the function has a practical behavior of needing something in Context to behave correctly, then it moves closer to influencing the control of your program
One example of inform is a request ID. Generally these are used in logging or other aggregation systems to group requests together. The actual contents of a request ID never change the result of an if statement and if a request ID is missing it does nothing to modify the result of a function.
Another example that fits the definition of inform is a logger. The presence or lack of a logger never changes the flow of a program. Also, what is or isn’t logged is usually not documented or relied upon behavior in most uses. However, if the existence of logging or contents of the log are documented in the API, then the logger has moved from inform to control.
Another example of inform is the IP address of the incoming request, if the only purpose of this IP address is to decorate log messages with the IP address of the user. However, if the documentation or expected behavior of your library is that some IPs are more important and less likely to be throttled then the IP address has moved from inform to control because it is now required input, or at least input that alters behavior.
A database connection is a worst case example of an object to place in a context.Value because it obviously controls the program and is required input for your functions.
The golang.org blog post on context.Context is potentially a counter example of how to correctly use context.Value. __ Let’s look at the Search code posted in the blog.
func Search(ctx context.Context, query string) (Results, error) {
// Prepare the Google Search API request.
// ...
// ...
q := req.URL.Query()
q.Set("q", query)
// If ctx is carrying the user IP address, forward it to the server.
// Google APIs use the user IP to distinguish server-initiated requests
// from end-user requests.
if userIP, ok := userip.FromContext(ctx); ok {
q.Set("userip", userIP.String())
}
// ...
}
The primary measuring stick is knowing how the existence of a userIP on the query changes the result of a request. If the IP is distinguished in a log tracking system so people can debug the destination server, then it purely informs and is OK. If the userIP being inside a request changes the behavior of the REST call or tends to make it less likely to be throttled, then it begins to control the likely output of Search and is no longer appropriate for Context.Value.
The blog post also mentions authorization tokens as something that is stored in context.Value. This clearly violates the rules of appropriate content in Context.Value because it controls the behavior of the function and is required input for the flow of your program. Instead, it is better to make tokens an explicit parameter or member of a struct.
Does Context.Value even belong? Link to heading
Context does two very different things: one of them times out long-running operations and the other carries request scoped values. Interfaces in Go should be about describing behaviors an API wants. They should not be grab bags of functions that happen to often exist together. It is unfortunate that I’m forced to include behavior about adding arbitrary values to an object when all I care about is timing out runaway requests.
Alternatives to Context.Value Link to heading
People often use Context.Value in a broader middleware abstraction. Here I’ll show how to stay inside this kind of abstraction while still not needing to abuse Context.Value. Let’s show some example code that uses HTTP middlewares and Context.Value to propagate a user ID found at the beginning of the middleware. Note Go 1.7 includes a context on the http.Request object. Also, I’m a bit loose with the syntax, but I hope the meaning is clear.
package goexperiments
import (
"context"
"net/http"
)
type HandlerMiddleware interface {
HandleHTTPC(ctx context.Context, rw http.ResponseWriter, req *http.Request, next http.Handler)
}
var function1 HandlerMiddleware = nil
var function2 HandlerMiddleware = nil
func addUserID(rw http.ResponseWriter, req *http.Request, next http.Handler) {
ctx := context.WithValue(req.Context(), "userid", req.Header.Get("userid"))
req = req.WithContext(ctx)
next.ServeHTTP(rw, req)
}
func useUserID(rw http.ResponseWriter, req *http.Request, next http.Handler) {
uid := req.Context().Value("userid")
rw.Write([]byte(uid))
}
func makeChain(chain ...HandlerMiddleware) http.Handler {return nil}
type Server struct {}
func (s *Server) ServeHTTP(rw http.ResponseWriter, req *http.Request) {
req = req.WithContext(context.Background())
chain := makeChain(addUserID, function1, function2, useUserID)
chain.ServeHTTP(rw, req)
}
This is an example of how Context.Value is often used in middleware chains to set up propagating a userID along. The first middleware, addUserID, updates the context. It then calls the next handler in the middleware chain. Later the user id value inside the context is extracted and used. In large applications you could imagine these two functions being very far from each other.
Let’s now show how using the same abstraction we can do the same thing, but not need to abuse Context.Value.
package goexperiments
import (
"context"
"net/http"
)
type HandlerMiddleware interface {
HandleHTTPC(ctx context.Context, rw http.ResponseWriter, req *http.Request, next http.Handler)
}
var function1 HandlerMiddleware = nil
var function2 HandlerMiddleware = nil
func makeChain(chain ...HandlerMiddleware) http.Handler { return nil }
type AddUserID struct {
OnUserID func(userID string) http.Handler
}
func (a *AddUserID) ServeHTTP(rw http.ResponseWriter, req *http.Request) {
userID := req.Header.Get("userid")
a.OnUserID(userID).ServeHTTP(rw, req)
}
type UseUserID struct {
UserID string
}
func (u *UseUserID) ServeHTTP(rw http.ResponseWriter, req *http.Request) {
rw.Write([]byte(u.UserID))
}
type ServerNoAbuseContext struct{}
func (s *ServerNoAbuseContext) ServeHTTP(rw http.ResponseWriter, req *http.Request) {
req = req.WithContext(context.Background())
chainWithAuth := func(userID string) http.Handler {
return makeChain(function1, function2, &UseUserID{
UserID: userID,
})
}
chainPartOne := &AddUserID{
OnUserID: chainWithAuth,
}
chainPartOne.ServeHTTP(rw, req)
}
In this example, we can still use the same middleware abstractions and still have only the main function know about the chain of middleware, but use the UserID in a type safe way. The variable chainPartOne is the middleware chain up to when we extract the UserID. That part of the chain can then create the next part of the chain, chainWithAuth, using the UserID directly.
In this example, we can keep Context to just ending early long-running functions. We have also clearly documented that struct UseUserID needs a UserID to behave correctly. This clear separation means that when people later refactor this code or try to reuse UseUserID, they know what to expect.
Why the exception for maintainers Link to heading
I admit carving out an exception for maintainers in Context.Value is somewhat arbitrary. My personal reasoning is to imagine a perfectly designed system. In this system, there would be no need for introspecting an application, no need for debug logs, and little need for metrics. The system is perfect so maintenance problems don’t exist. Unfortunately, the reality is that we do need to debug systems. Putting this debug information in a Context object is a compromise between the perfect API that would never need maintenance and the realities of wanting to thread debug information across an API. However, I wouldn’t particularly argue with someone that wants to make even debugging information explicit in their API.
Try not to use context.Value Link to heading
You can get into way more trouble than it’s worth trying to use context.Value. I empathize about how easy it is to just add something into context.Value and retrieve it later in some far away abstraction, but the ease of use now is paid for by pain when refactoring later. There is almost never a need to use it and if you do, it makes refactoring your code later very difficult because it becomes unknown (especially by the compiler) what inputs are required for functions. It’s a very contentious addition to Context and can easily get one in more trouble than it’s worth.